 : Aid Visually Impaired People Walking by Vision Language Model
: Aid Visually Impaired People Walking by Vision Language Model
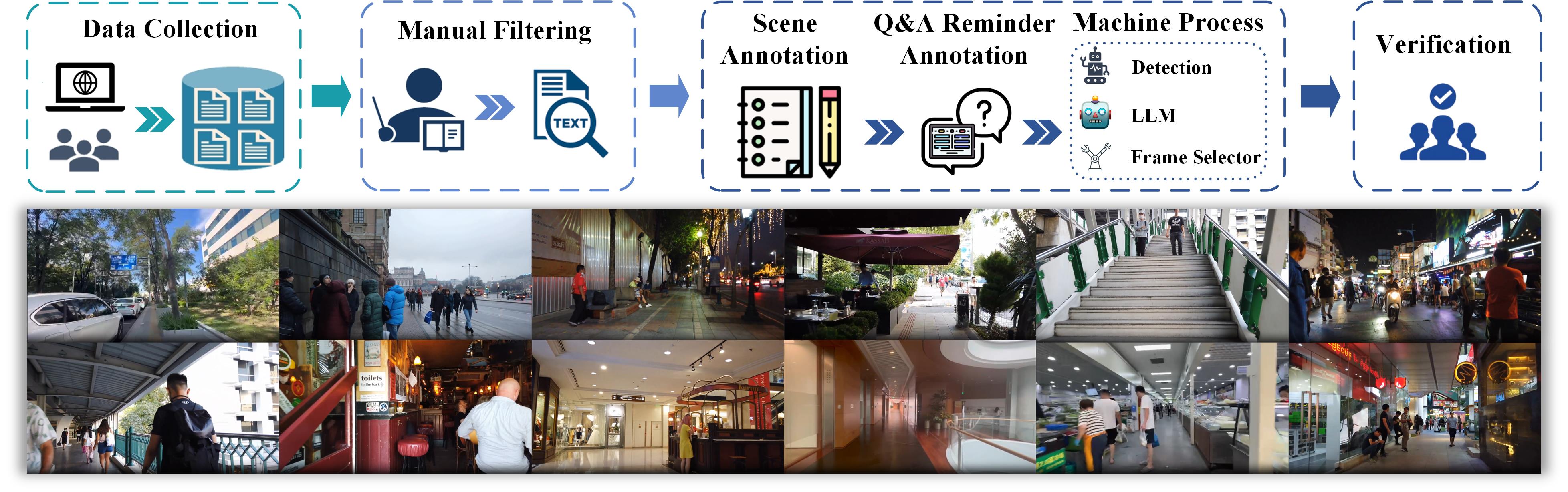
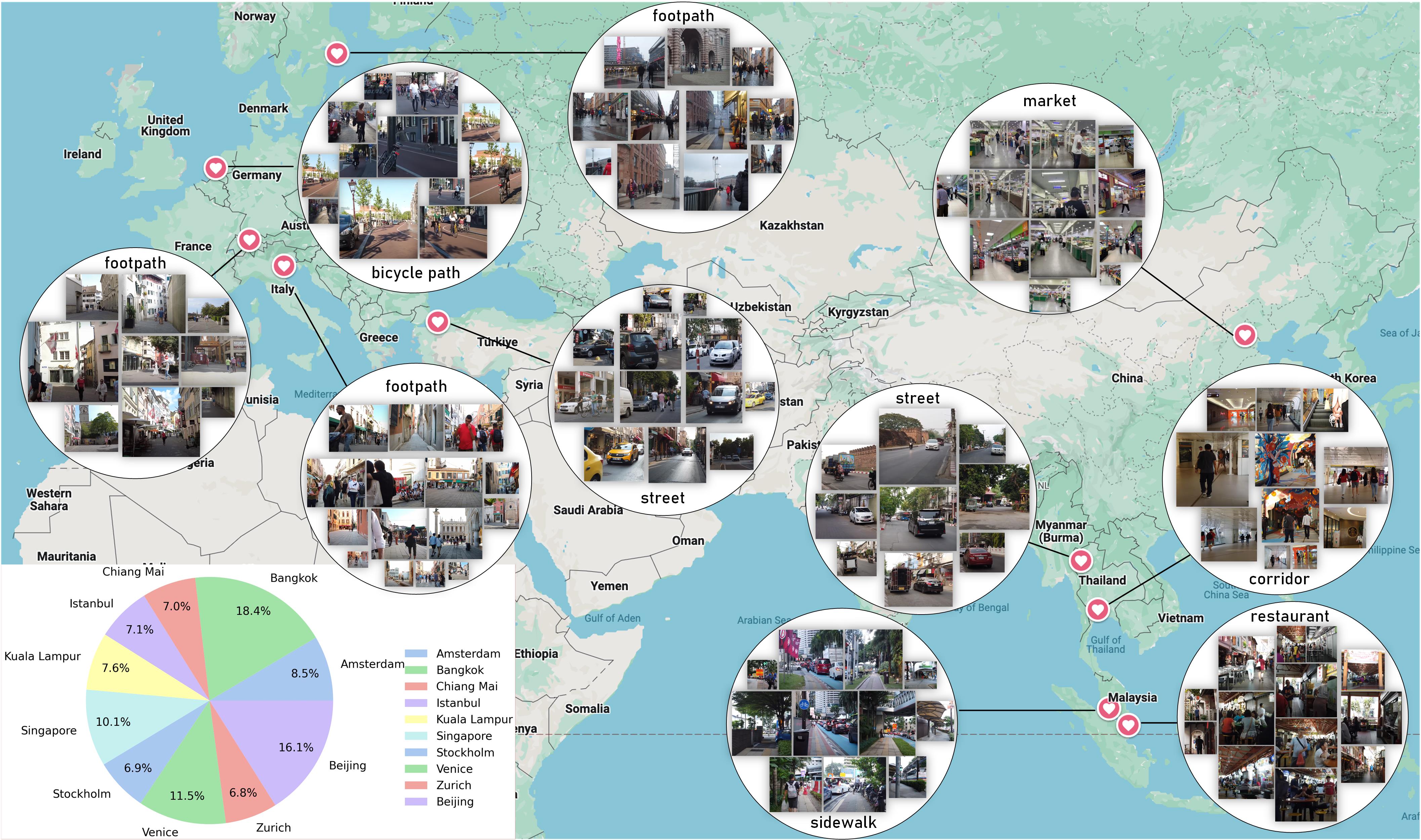
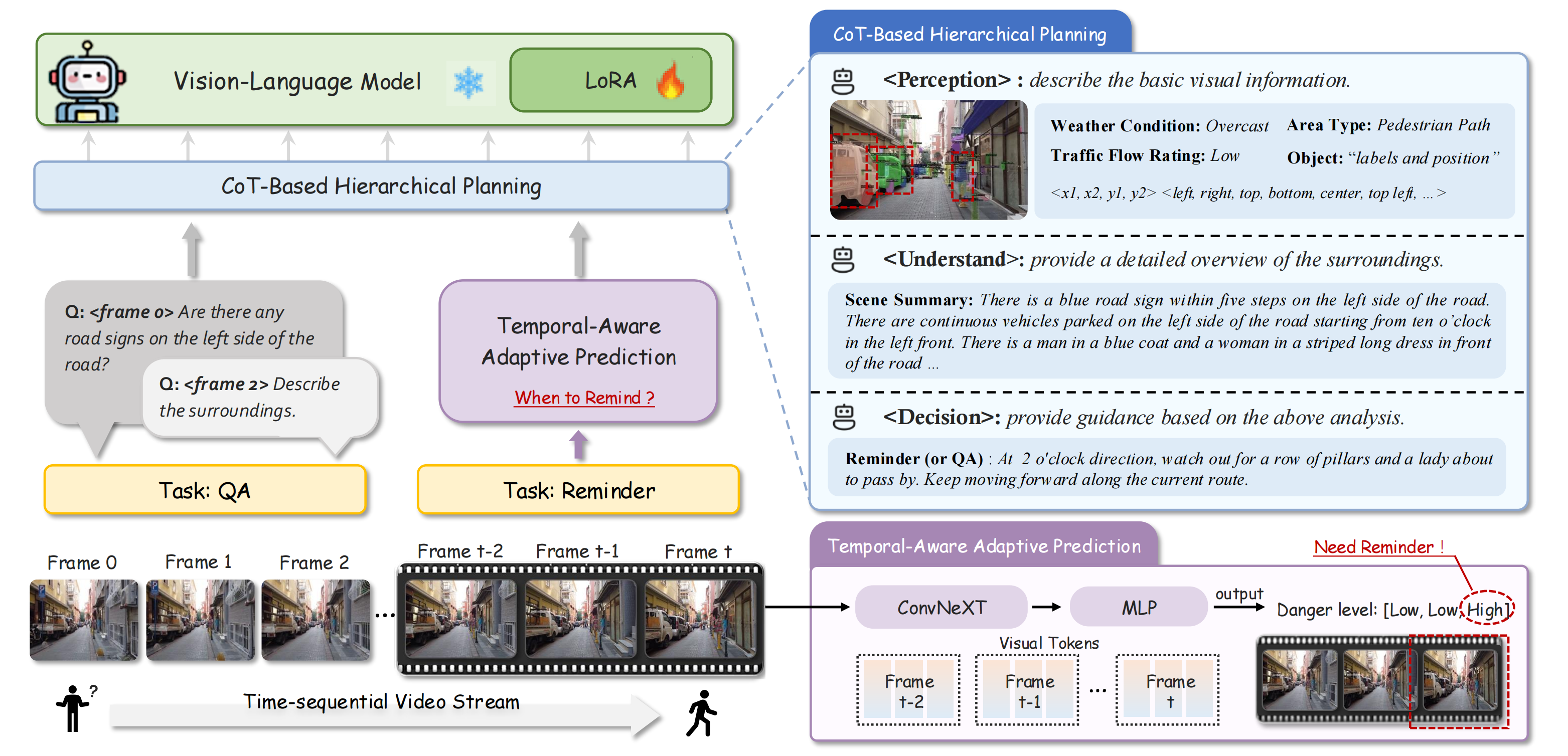
Approximately 200 million individuals around the world suffer from varying degrees of visual impairment, making it crucial to leverage AI technology to offer walking assistance for these people. With the recent progress of vision-language models (VLMs), employing VLMs to improve this field has emerged as a popular research topic. However, most existing methods are studied on self-built question-answering datasets, lacking a unified training and testing benchmark for walk guidance. Moreover, in blind walking task, it is necessary to perform real-time streaming video parsing and generate concise yet informative reminders, which poses a great challenge for VLMs that suffer from redundant responses and low inference efficiency. In this paper, we firstly release a diverse, extensive, and unbiased walking awareness dataset, containing 12k video-manual annotation pairs from Europe and Asia to provide a fair training and testing benchmark for blind walking task. Furthermore, a WalkVLM model is proposed, which employs chain of thought for hierarchical planning to generate concise but informative reminders and utilizes temporal-aware adaptive prediction to reduce the temporal redundancy of reminders. Finally, we have established a solid benchmark for blind walking task and verified the advantages of WalkVLM in stream video processing for this task compared to other VLMs.

Weather Condition: Sunny
Reminder task
Area Type:Pedestrian Path
Danger Level:Mid
Traffic Flow Rating:Low
Summary:on the sidewalk on the right side of the road, there is a downward step on the left, a yellow car passes on the left side of the road, there is a row of green plants on the right, there is a row of trees at one o'clock direction, there is a sign at two o'clock direction, there are cars parked on the roadside at eleven o'clock direction, the current road is narrow and there are few pedestrians
Reminder:at 11 o'clock direction there is a car, at 1 o'clock direction there is a sign, be careful to avoid.
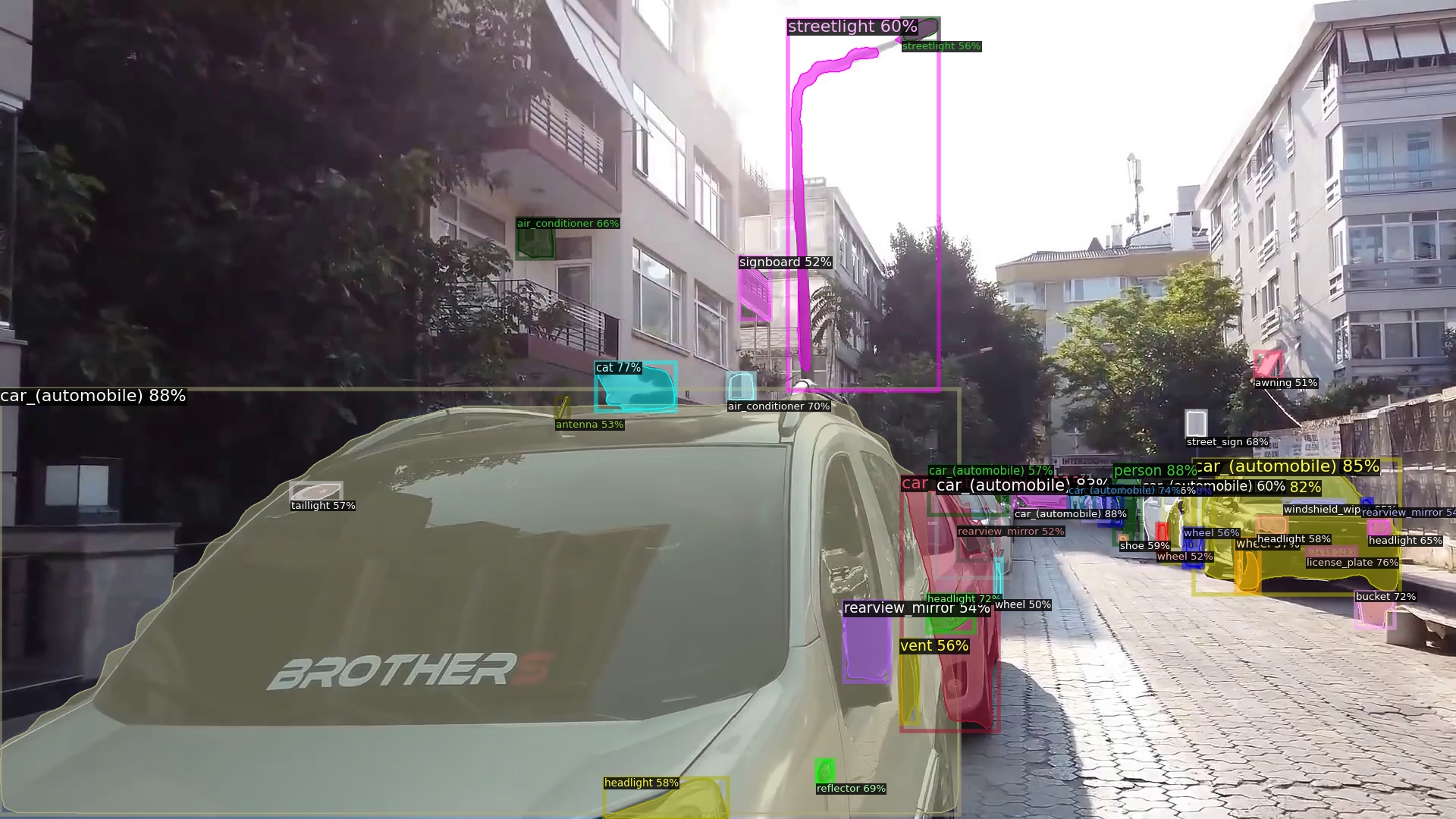
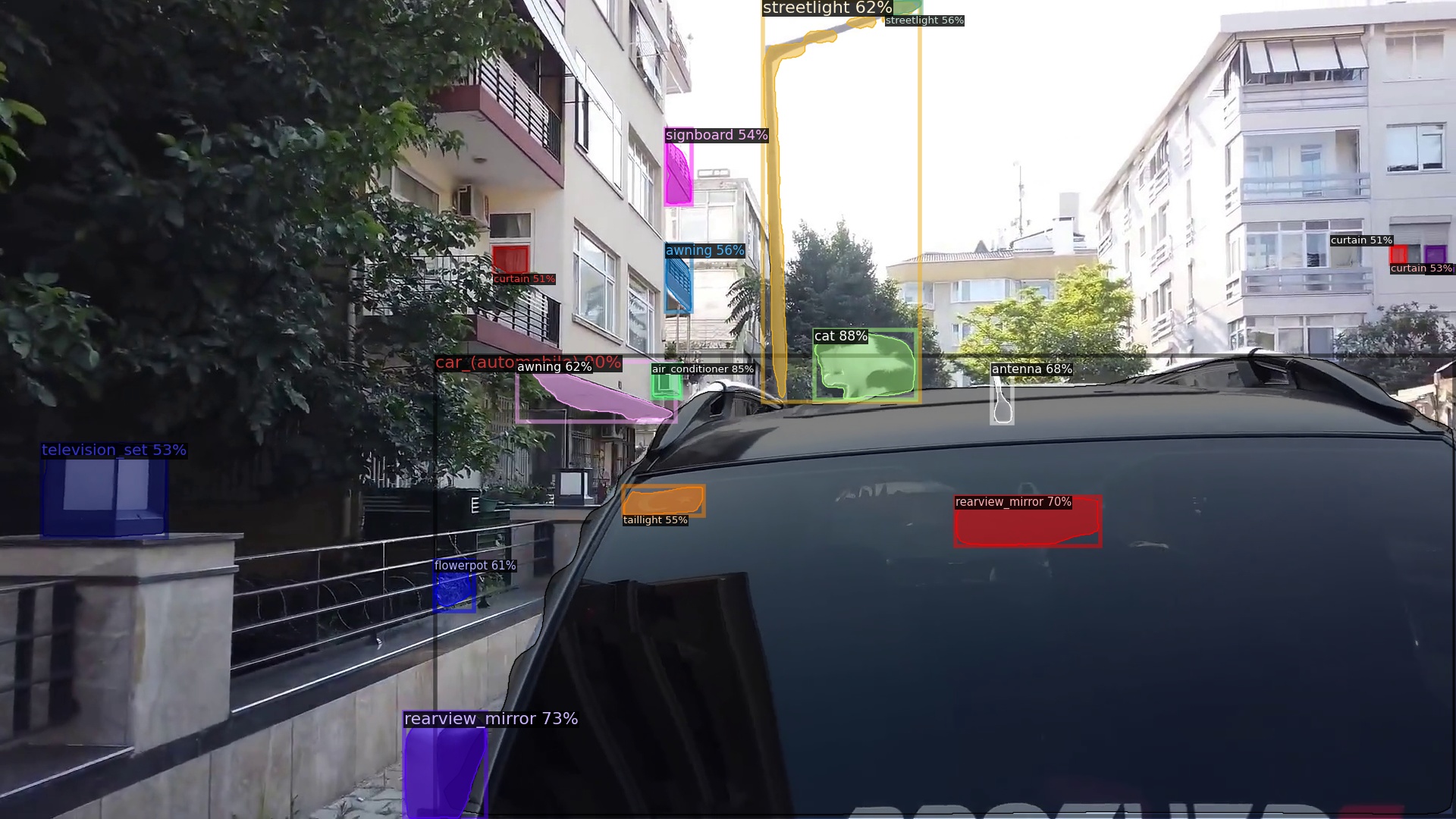
Target detection labels. Right-click to open the image in a new tab.
 |
 |
 |
 |
 |
 |
 |
 |
 |
Weather Condition: Overcast
Reminder task
Area Type:Pedestrian Path
Danger Level:High
Traffic Flow Rating:High
Summary:walking on a stone bridge. left side is red, right side is paved with stone bricks. there are stone railings on both sides of the bridge. there are many trees below the opposite side and both sides of the bridge. there is a pedestrian in a black coat about five steps ahead. the large flow of people is mainly concentrated about fifteen steps ahead. there is no road nearby and the traffic flow is zero.
Reminder:at 10 o'clock direction, there are pedestrians passing by. please move slowly towards 11 o'clock direction.
Target detection labels. Right-click to open the image in a new tab.
 |
 |
 |
 |
 |
 |
 |
 |
 |
Weather Condition: Overcast
QA task
Area Type:Pedestrian Path
Danger Level:Low
Traffic Flow Rating:Low
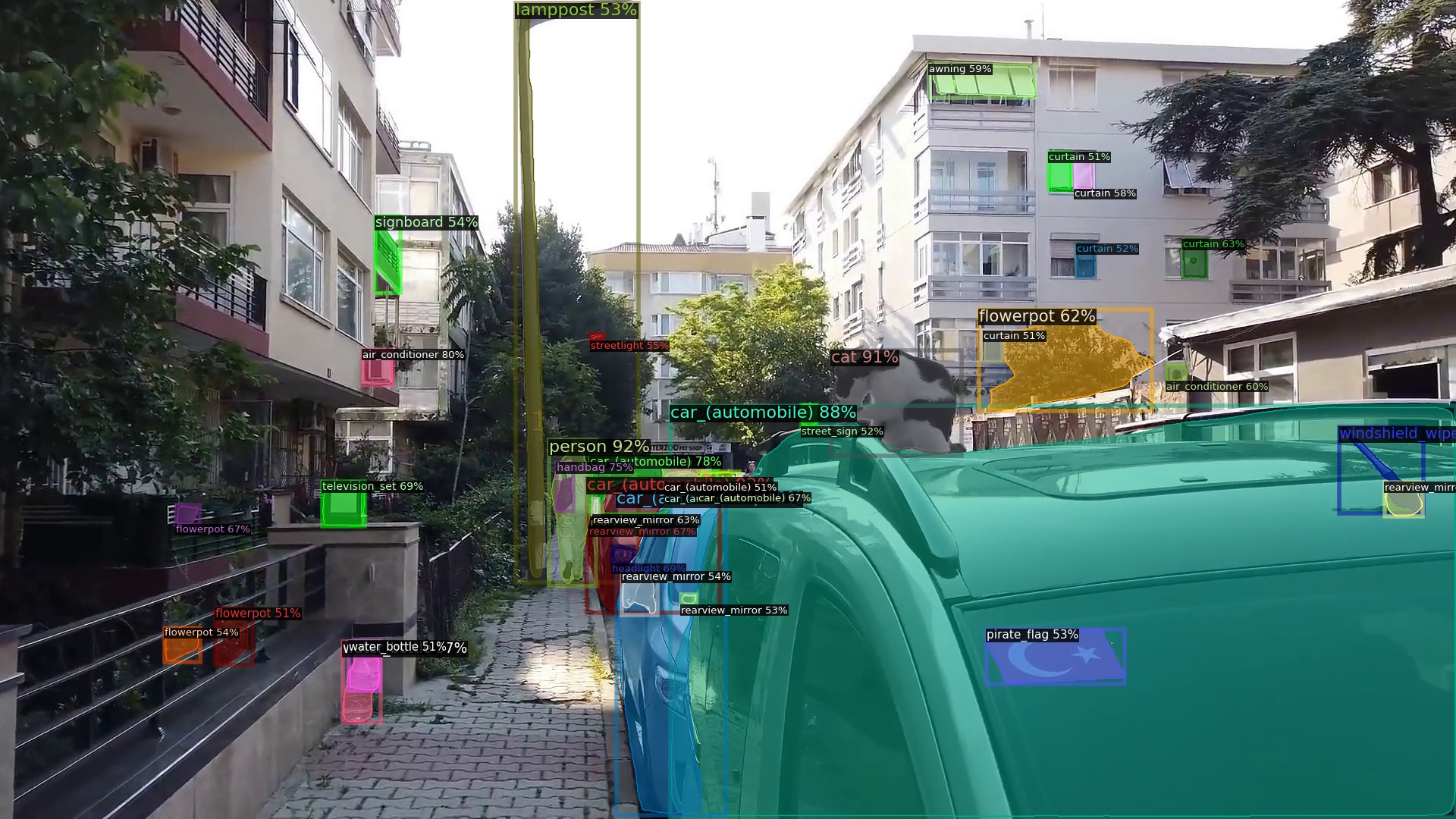
Summary:on a walking path, there are rows of cars parked in front and on the right. on the silver - grey car on the right, there is a black - and - white cow cat squatting. about 15 steps ahead, there is a pedestrian in white. on the left, there is a row of metal railings, and inside the railings are residential buildings. the road is narrow, there are few pedestrians and no vehicles passing.
Q:how about current road situation?
A:the current is a small road with cars parked on both sides. there are few pedestrians on the road. now walk to the left side of the road which is relatively narrow. be careful to avoid the cars parked on the right side and pay attention to safety.
Target detection labels. Right-click to open the image in a new tab.
 |
 |
 |
 |
 |
 |
 |
 |
 |
Weather Condition: Cloudy
QA task
Area Type:Pedestrian Path
Danger Level:Low
Traffic Flow Rating:Mid
Summary:on the walkway, it is sunny, with green belts on the right, shops on the left, the road is narrow, there is a tree and a sign at one o'clock, and there is a bicycle straight ahead, and there are few pedestrians on the current road.
Q:describe the scene?
A:now there is a bicycle parked on the road 5 steps ahead of you. you need to deviate towards the 11 o'clock direction.
Target detection labels. Right-click to open the image in a new tab.
 |
 |
 |
 |
 |
 |
 |
 |
 |


We are committed to providing walking assistance to approximately 200 million visually impaired individuals worldwide through Vision-Language Model (VLM) technology, improving their quality of life. We have introduced the WalkVLM model and the walking awareness dataset, aimed at generating concise and informative walking reminders. We call on all sectors of society to pay more attention to this group, promote technology for good, and help them better integrate into society. Additionally, we hope to further crowdsourcing more data and resources, making our services more comprehensive and effective.
If you use our work in your research, please cite:
@article{yuan2024walkvlm,
title={Walkvlm: Aid visually impaired people walking by vision language model},
author={Yuan, Zhiqiang and Zhang, Ting and Deng, Ying and Zhang, Jiapei and Zhu, Yeshuang and Jia, Zexi and Zhou, Jie and Zhang, Jinchao},
journal={arXiv preprint arXiv:2412.20903},
year={2024}
}